Replicating a PostgreSQL Cluster to Redshift with AWS DMS
The Good, the Bad, and the Ugly




Jesús Sánchez
Over the past year, the RevenueCat team has been building a new data platform to support data-driven features like Lists (which enables you to cohort and analyze your customers) and the new version of Charts (which helps you analyze and visualize your app business).
At RevenueCat, our data originates from a PostgreSQL transactional database. However, several of our features—like Lists and Charts—are powered by a Redshift instance, which we use for data analytics.
For context, our PostgreSQL database processes more than 800 changes every second. That’s over 70 million rows per day. So it was crucial for us to find a reliable replication mechanism.
In this post, we’ll talk about the pros and cons of using AWS DMS to replicate PostgreSQL to Redshift. We hope to help other developers and organizations with this important decision and provide some guidance for potential issues you might encounter when using DMS in a production environment.
Using AWS DMS as a replication tool
Our team decided to use AWS DMS to replicate our PostgreSQL production database to Redshift. DMS lets you set up a replication scheme in just a few steps. We won’t go over how to actually set up DMS in this post, since there are too many different configurations depending on whether the source/target is on-premises, IaaS, or PaaS.
Before we get into how to configure DMS, it’s important to understand some terms. A DMS source is a system from which you want to replicate data. It might be a relational database (such as PostgreSQL or MySQL), a document database (like Amazon DocumentDB), or even an S3 bucket. A DMS target is the destination of the replication process. Just like sources, targets can be a relational or document database or an S3 bucket. You can find more information on the supported sources and targets in the DMS documentation.
Here’s a general overview of what the architecture of the replication process looks like (note that the DMS replication instance runs in an EC2 instance):
How does it work?
There’s a lot of great documentation on AWS DMS, so we suggest reading up on the key components if you’re considering using DMS for your own purposes. However, there are some workflows that aren’t clear in the documentation, so we wanted to take a moment to clarify.
The process works like this:
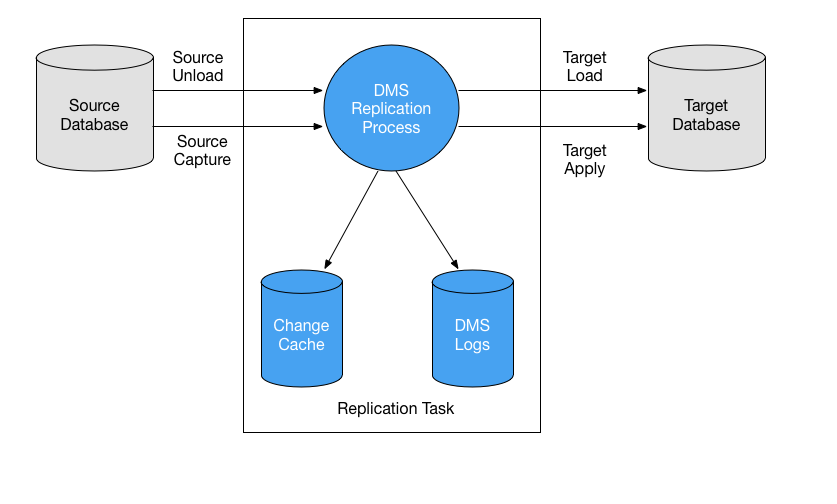
For a PostgreSQL to Redshift scenario, the replication task works like this:
- The DMS task reads the changes from the PostgreSQL replication slot (the “Source Capture” step in the image above).
- At some point, based on the BatchApplyTimeoutMin, BatchApplyTimeoutMax and BatchApplyMemoryLimit settings, a batch of changes is applied to the target (the “Target Apply” step in the image above).
- The DMS task generates a set of files with the changes to be applied.
- DMS creates an intermediate table with the following naming convention:
awsdms_changes*. (For example:awsdms_changes31fdb6d65ekz99b4) - This table is used to apply all of the
INSERTs,DELETEs, and bulkUPDATEs.
Then, DMS sweeps the whole intermediate table and performs the operations like this:
INSERTrows 1 through 1000 into yourtable1.INSERTrows 1001 through 5300 into yourtable2.DELETErows 5301 through 5400 from yourtable2.UPDATErows 5401 through 8000 in yourtable3 .- When all the changes have been applied, the process starts over again at step 1.
The pros and cons of using DMS
The Pros:
- Security. One of the biggest factors for us was that we use AWS for all of our systems, and DMS allowed us to avoid having our data leave the VPC. We didn’t want any third parties to process or store our data outside of our VPC.
- Easy to use. You can set up DMS in less than a dozen clicks. And the AWS UI is pretty straightforward—you can set up DMS using a wizard or directly in JSON (which is good for versioning the config).
- Costs. It would cost a lot to develop a tool like DMS in-house. Another benefit of DMS is that they don’t charge you for the product itself—you only pay for the EC2 instances where the replication tasks are running.
- Good documentation. There are tons of articles out there on configuring DMS, best practices, etc.
- Automatic DDL propagation. This is probably one of the most powerful features of DMS. It automatically propagates DDL changes in the source to the target database. This means that developers don’t have to worry about migrating the replication target schema. (This is what convinced us to try DMS!)
- It works 99% of the time. As we’ll see later, there are some scenarios where DMS has some limitations, but overall, it works really well.
- Cloudwatch metrics. If you’re going to use DMS, you need to set up alerts, especially for target latency. We strongly suggest spending some time configuring good alarms—it will save you a lot of time and headaches in the long run.
The Cons:
- Complex product. DMS is a general-purpose replication software—it supports a lot of sources and a lot of targets, and every source and target has its own particular configuration details. At the same time, there are also a lot of similarities between them. It can be hard to tell what configuration settings work for which sources and targets.
- Missing changes. We don’t know why, but from time to time, the replication process skips a single row. It seems to happen in tables with a high volume and number of changes per second. Another thing to watch out for: sometimes when the replication instance is rebooted, changes might be lost.
- Replication instance memory leak. Replication tasks run on top of an EC2 instance. The size of the instance doesn’t matter, but tasks drain memory from the instance until the task fails and needs to be rebooted.
- The one-by-one mode switch. We suppose there must be some justification for this, but every time a bulk
UPDATEstatement affects fewer rows than expected because there is a missing row, it switches to one-by-one mode, applies all theUPDATEs one by one, then switches back to bulk mode. This issue (and the missing changes one) can heavily impact your production environment because it makes the target latency skyrocket. So, you’d better set some Cloudwatch alarms for the target latency metric, or you might get into trouble if your source database replicates many changes per second or minute. - Task state not reflecting what is going on. We saw some scenarios where the task had actually failed, but the state didn’t update to Failed.
- Booleans are mapped to varchar. In Redshift, you can’t cast varchar to boolean directly. As DMS uses an intermediate table where all the columns are varchar, booleans are translated from PostgreSQL to Redshift as varchar(14). We tried to force DMS to use boolean as target, but it failed, which made the task switch to one-by-one mode. In short, booleans are strings, and that’s not the most convenient thing for us.
Lessons learned
Diving into our specific configuration doesn’t make much sense because we pretty much followed the AWS DMS documentation. If you’re considering using DMS, we strongly suggest reading the specific considerations for your source and target systems. For our purposes, we followed the documentation on using PostgreSQL as a source and using Redshift as a target.
Instead, we think it would be useful to share specific details that we didn’t find in the documentation that might be useful for you when replicating from PostgreSQL to Redshift.
The one-by-one switch issue
As explained in the cons section, when a bulk UPDATE is applied to fewer rows than expected, the DMS task switches to one-by-one mode.
DMS determines how many rows will be affected by an UPDATE statement by subtracting the indexes related to that operation. For instance, let’s say this is the UPDATE query:
1UPDATE your_table
2SET -- skipping this part
3FROM awsdms_changes31fdb6d as changes -- the DMS managed intermediate table
4WHERE your_table.id = changes.seg1 AND changes.seq >= 1 and changes.seq <= 1000In this example, if the UPDATE affects fewer than 1000 rows, DMS will switch to one-by-one mode.
At RevenueCat, we created a side project to deal with all the DMS issues that we found along the way. For this specific purpose, we created a daemon (replication checker) that runs every three minutes and checks the number of UPDATEs in the cluster related to DMS (this is pretty easy to do because DMS adds a comment to the UPDATE statement with the DMS version).
When DMS switches to one-by-one mode, the replication checker kicks in and fixes it by performing the following actions:
- When the number of
UPDATEsin the cluster is greater than a threshold (this might be calculated dynamically by checking the historical number ofUPDATEsand the delta ofUPDATEscompared to the last X minutes, but we ended up setting a fixed value in order to prevent false positives), the replication fixer starts the fixing process. - The fixer will look for the latest
UPDATEthat was rolled back (this is done by querying Redshift internal views). - Once the
UPDATEis found, the replication fixer parses it to find the AWS intermediate table that is being used for theUPDATE, then extracts its name, the target table, and the range of rows being updated. - Then, it looks for the missing row (or rows) by performing a
LEFT JOINbetween the intermediate table and the target table. - When the IDs are found, the fixer retrieves the missing row(s) from the source database.
- With the actual row, the fixer generates the
INSERTstatement, converting data types from PostgreSQL to Redshift accordingly. When theINSERTstatement is generated, the fixer executes it against the Redshift cluster. - Finally, the replication task is stopped and resumed. After that, the checker waits for 15 minutes to check again.
This process has three main components:
- The replication checker, which assesses whether or not the fixer should kick in
- The fixer, which dives into the Redshift internal views to get the ID of the missing row
- The data type translator—not all the PostgreSQL data types are supported in Redshift (array, JSON, etc). This component translates those types to something that can be inserted into a Redshift table.
Dealing with Redshift maintenance windows
Normally, Redshift automatically performs a maintenance window. You can choose when this maintenance window happens or even defer it.
Why does this matter? In the past, we faced some edge case situations where the maintenance window rebooted the Redshift cluster in the middle of an UPDATE statement, causing the DMS task to silently fail (meaning the task wasn’t marked as failed, but under the hood it stopped working).
We created a tool that stops all the configured replication tasks at a specified time and resumes them 35 minutes later. You might be wondering: why 35 minutes? Let’s say that you have set up a weekly maintenance window on Wednesday at 11:00 AM UTC. We noticed that normally the maintenance window works like this:
- At 11:00 AM UTC the Redshift cluster is marked as Maintenance.
- Between 2 and 6 minutes after the cluster is marked, the cluster is rebooted.
- The reboot process takes around 1-3 minutes.
- So, usually, the maintenance window is finished by 11:10 AM UTC.
The tool we created stops all the replication tasks at 10:55 AM UTC and resumes all of them at 11:30 AM UTC. This is where the magic number (35 minutes) comes from. We think we could resume the tasks earlier, but we prefer to wait until 11:30 AM UTC to prevent any outages in case Redshift shifts its maintenance window by a few minutes.
Preventing the DMS instance from running out of memory
DMS seems to have a memory leak. We can’t say for sure because DMS is a black-box product, so we don’t know anything about its internals.
The fact is that DMS replication instances run out of memory around twice a week. We created a tool that checks how much memory is left in the instance and, if the amount of available memory is lower than 1.5 GB, tasks are stopped and resumed. This causes the instance memory to bounce back to a value close to the instance maximum.
Previously, we were rebooting the instance instead of stopping and resuming the tasks, but we realized that rebooting the instance led to data loss.
Fill missing rows
As we discussed before, there are some scenarios where DMS fails to replicate changes. As far as we know, these scenarios are:
- When the cluster reboots in the middle of an
UPDATEstatement. - DMS task failures, such as the replication instance running out of memory.
- Sometimes it just happens. We don’t know why. It doesn’t happen every day, though.
Since we don’t have control over this process, we created a tool that checks each day to ensure that all the source database rows for a given day were successfully replicated to Redshift.
This works because all the tables that we are replicating have monotonically increasing primary keys that we can leverage to bind which IDs belong to a given day.
How it works is similar to what we talked about with one-by-one mode. Essentially:
- For each table configured in DMS, we search the target database for the maximum and the minimum value of the primary key.
- We dump all those identifiers from the source to a file and load them in Redshift.
- Once we have all the IDs for a day in Redshift, we perform a
LEFT JOINto find the missing IDs. - If there are missing IDs, we pull the whole row from the source.
- For each missing row, an
INSERTstatement is generated, taking into account how PostgreSQL data types map to Redshift. - Finally, we insert those rows into the Redshift table.
We automated this process to run every day during low-traffic hours.
Don’t delegate the target table creation
When a DMS replication task is created, you can specify the target table structure by manually creating the tables in the target database, or you can let DMS create the tables for you. From our experience, the compression encoding that DMS automatically chooses might not be optimal. If you’re not sure which encoding to use, a reasonable approach would be:
- Create a PoC/Development Redshift cluster to be used as a target that is safe to mess around with.
- Create a DMS replication task in full load mode with the target tables to be replicated.
- Don’t manually create the tables in the cluster.
- Run the DMS replication task. If you have massive tables, let the task run for an hour or more so the tables can be filled.
- When the full load finishes or you stop it after a few hours, run the
ANALYZE COMPRESSIONstatement. Reminder:ANALYZE COMPRESSIONis a heavy operation that you should not run on production environments. As noted in the documentation: “ANALYZE COMPRESSIONacquires an exclusive table lock, which prevents concurrent reads and writes against the table. Only run theANALYZE COMPRESSIONcommand when the table is idle.” - When the
ANALYZE COMPRESSIONstatement is finished, you can generate a SQL creation script for your target tables in Redshift and run it in the production cluster prior to the replication task start.
Conclusion
After a year of production usage, we’ve decided that AWS DMS is an interesting product with lots of potential, but in some ways does not feel mature.
It helped us move our production PostgreSQL cluster data to Redshift, which is something that we tried a few times before without success. We still spent substantial engineering time on the internal tooling, but we think that it was worth it. Thanks to AWS updates and our internal tooling, we’ve found a way to make DMS work for us, and we now feel like we can safely use it in a production environment.
If you’re considering using DMS as a replication tool, we hope that you found this post useful. We focused on the specific details of replicating from PostgreSQL to Redshift, but we think that many of the lessons we learned along the way can be applied to other use cases.
In-App Subscriptions Made Easy
See why thousands of the world's tops apps use RevenueCat to power in-app purchases, analyze subscription data, and grow revenue on iOS, Android, and the web.





